Regression is a statistical method used to model the relationship between a dependent variable
(the variable we want to predict) and one or more independent variables (predictors).
It allows us to estimate, predict, and understand the effects of predictors.
A general linear regression model is written as:
y = β₀ + β₁x₁ + β₂x₂ + ... + βₚxₚ + ε
y: dependent variable
x₁ … xₚ: independent variables
β₀ … βₚ: model coefficients
ε: error term (residuals)
Linear regression minimizes the Residual Sum of Squares (RSS):
RSS = Σ (yᵢ - ŷᵢ)²
This is known as the Ordinary Least Squares (OLS) solution. The goal is
to find the line (or hyperplane) that minimizes the difference between predicted and actual values.
2. Ridge Regression (L2 Regularization)
Ridge regression modifies OLS by adding a penalty proportional to the sum of the squares of the coefficients:
RSS + λ Σ βᵢ²
λ (lambda) controls regularization strength.
Large λ → coefficients shrink → reduces variance but may increase bias.
Ridge shrinks coefficients but keeps all features in the model.
Good for handling multicollinearity among predictors.
3. Lasso Regression (L1 Regularization)
Lasso regression adds a penalty proportional to the sum of absolute values of coefficients:
RSS + λ Σ |βᵢ|
Lasso can shrink some coefficients exactly to zero → automatic feature selection.
Large λ → many coefficients are zeroed out → sparse model.
Small λ → behaves like ordinary linear regression.
4. Interactive Visualization
Use the slider to change λ and observe how coefficients shrink and residuals are affected.
Gray dashed lines show residuals (difference between actual and predicted values).
Question: Can a Linear Regression find correlations between various Lifestyle factors?
Hello friends, today we are going to look at the Life Style Data dataset by Omar Essa
Libraries Used:
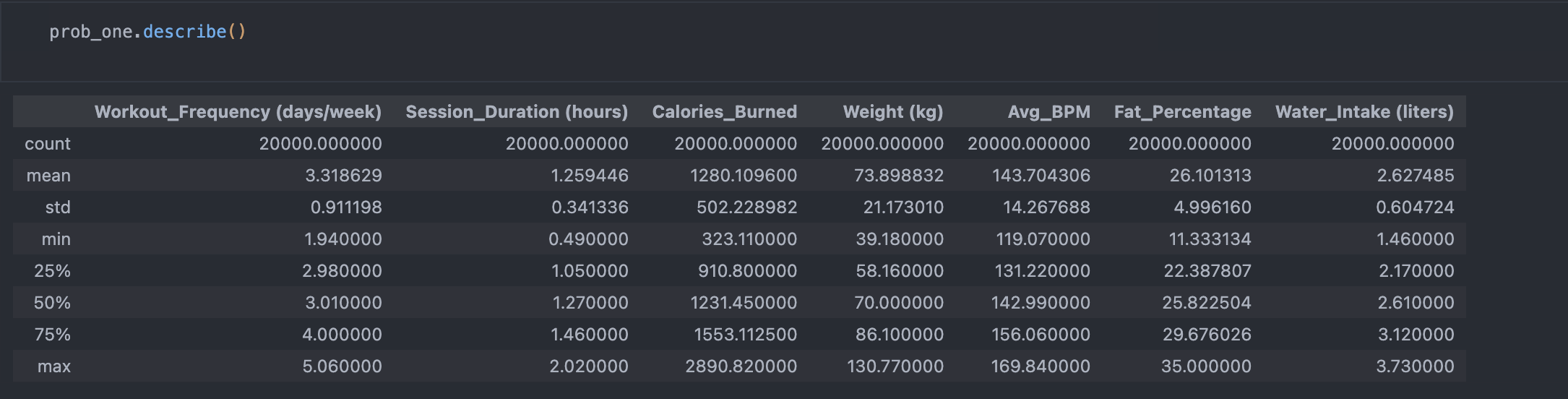
Dataset Info
prob_one is the variable that clean_prob_one() function was used on variable df:
Life Style Data dataset
This dataset has 2 files and 108 columns. Final_data.csv and meal_metadata.csv Some of the columns included are: Age, Gender, Weight (kg), Height (m), Max_BPM, Avg_BPM, Resting_BPM, Session_Duration (hours), etc.
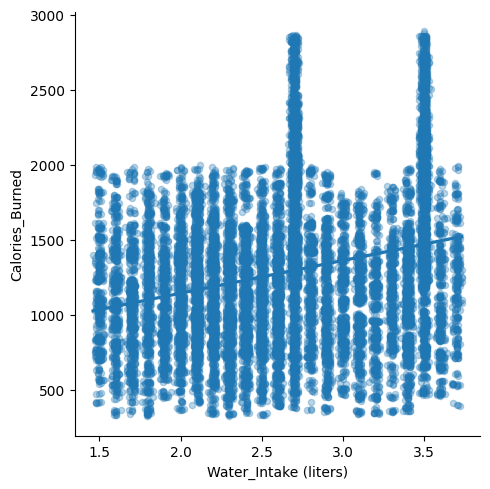
We are attempting to look if there are any correlational factors between columns and datapoint. At first glance you would think there would be obvious correlational pairs such as Workout_Frequency and Calories_Burned, however after spending multiple hours attempting to find correlational pairs. I was left shocked with multiple factors genuinely seeming to act independently regardless of other columns seeming related on paper, diving deeper into the data showed a different story.
Preprocessesing
This dataset was huge, and the pre-processesing was definitely a continous process. For all three experiments I had to create multiple variables of the data file. I had to create multiple functions that targeted specific columns in order to select specific columns for testing on linear regression models. I also found it easier to make testing functions which would make the training and testing operations simpler by simply passing the dataset variable features into a function.
I even tried going into the more specifics like going into the "Name of Exercise", like seeing if there would be a strong correlation within an exercise like bench press.
I had to check out the dataset information, here are the columns for Final_Data.csv:
The pre-processesing cleaning phase was pretty much a constant phase when doing this project. I created a bunch of functions to single out columns to attempt to solve my linear regression problem. I've learned that using functions to clean up a dataframe is usually the best option, due me being able to apply a custom set of pre-processesing steps to multiple dataframe variables if I wanted to.
Visualizations
I wanted to show some visualizations of the data
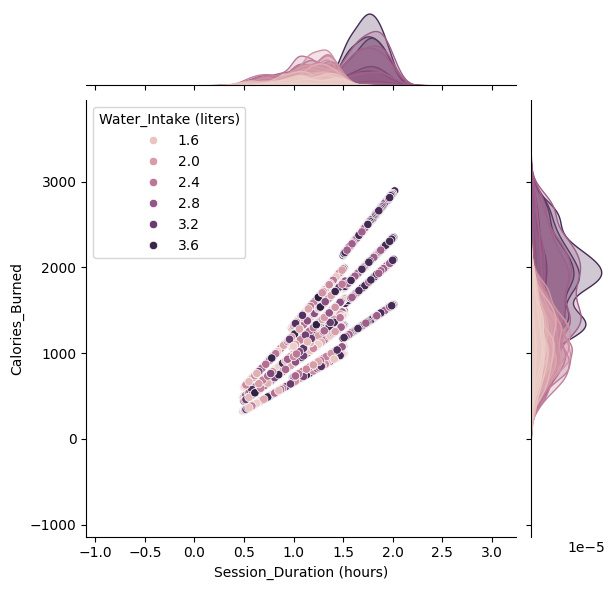
I created a bunch of visualizations in order to see correlations within the data. Visualizations are also important to see the distributions of the data, they make the process of how to proceed with the data much easier.
Analyzation
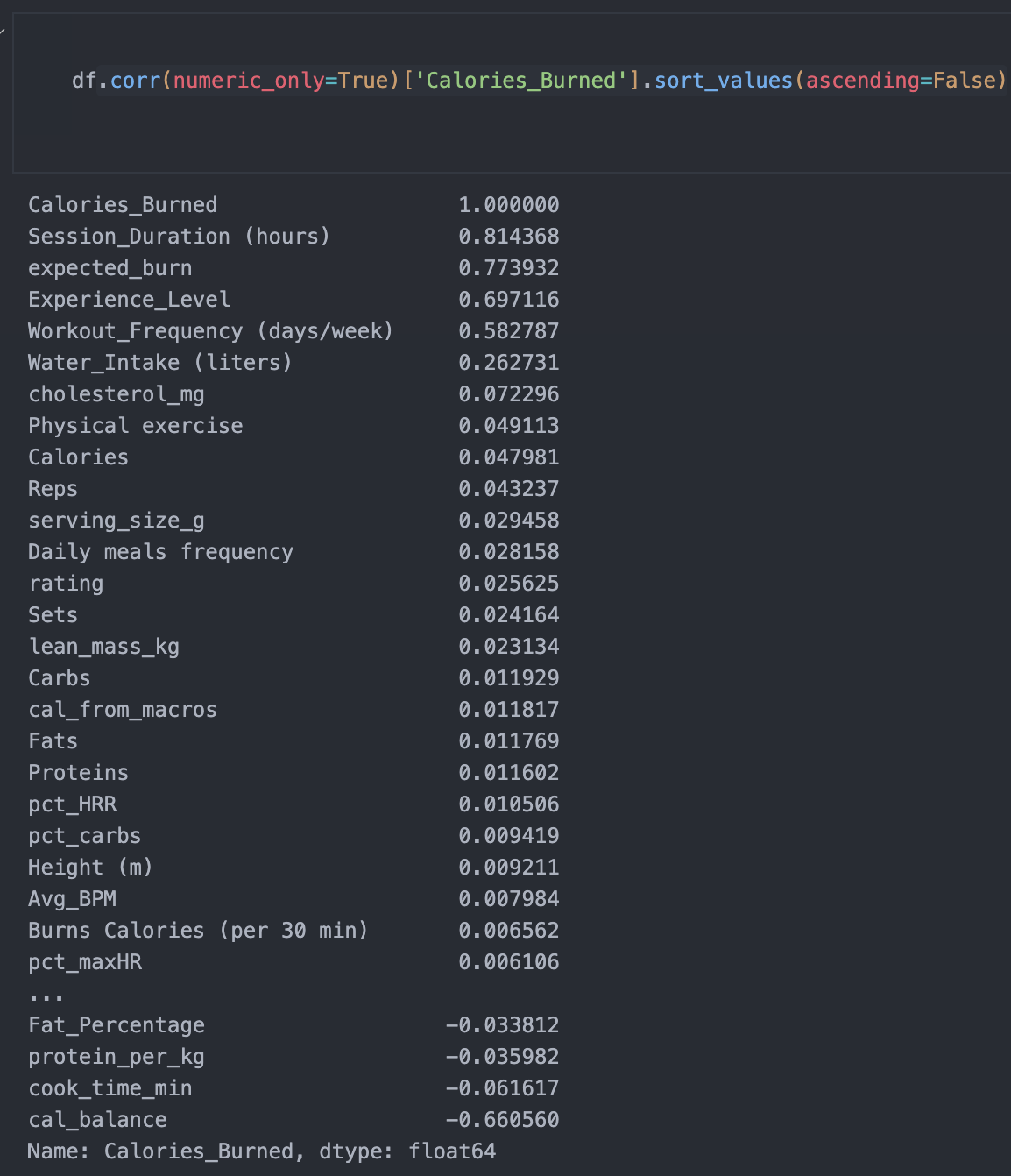
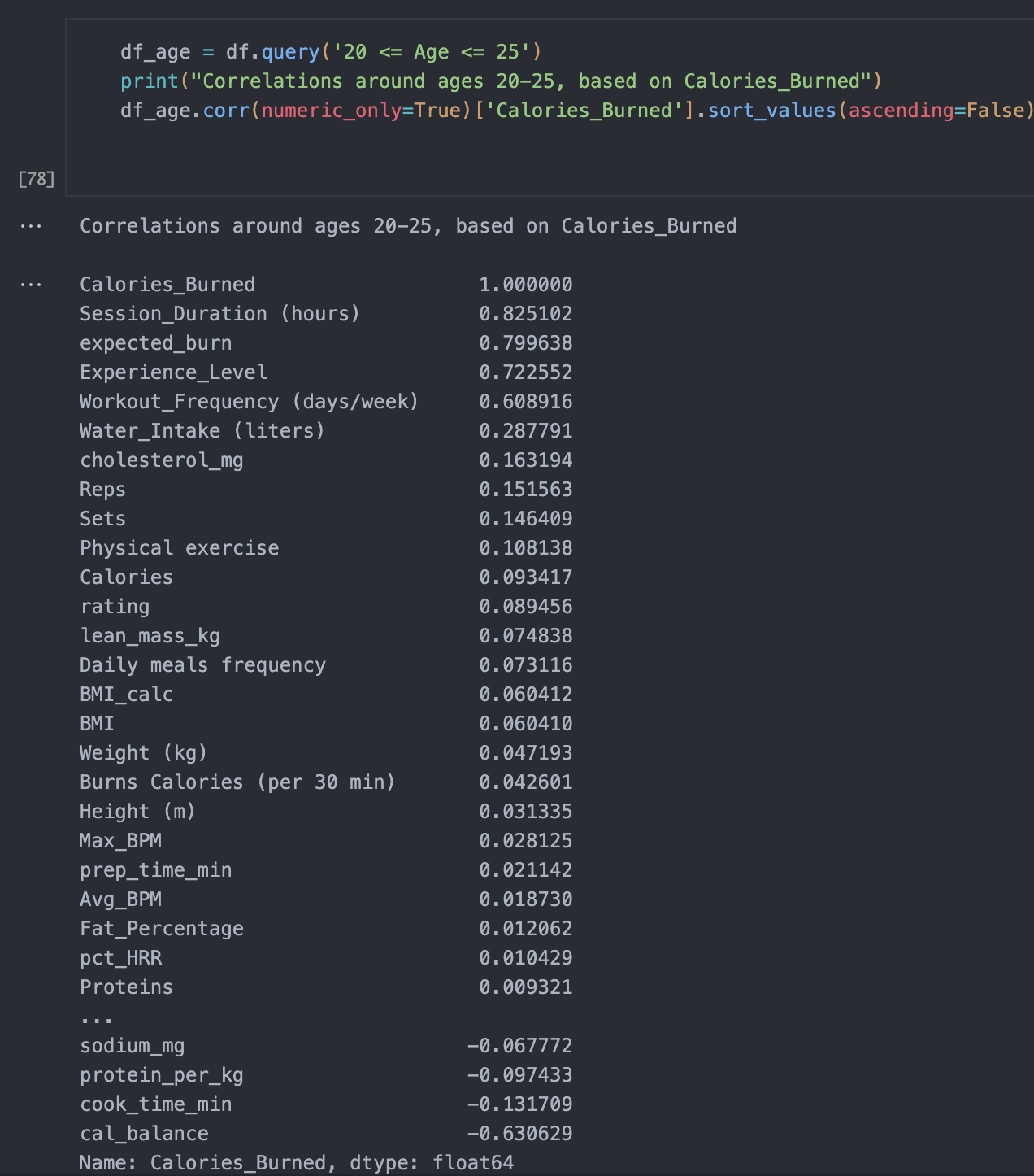
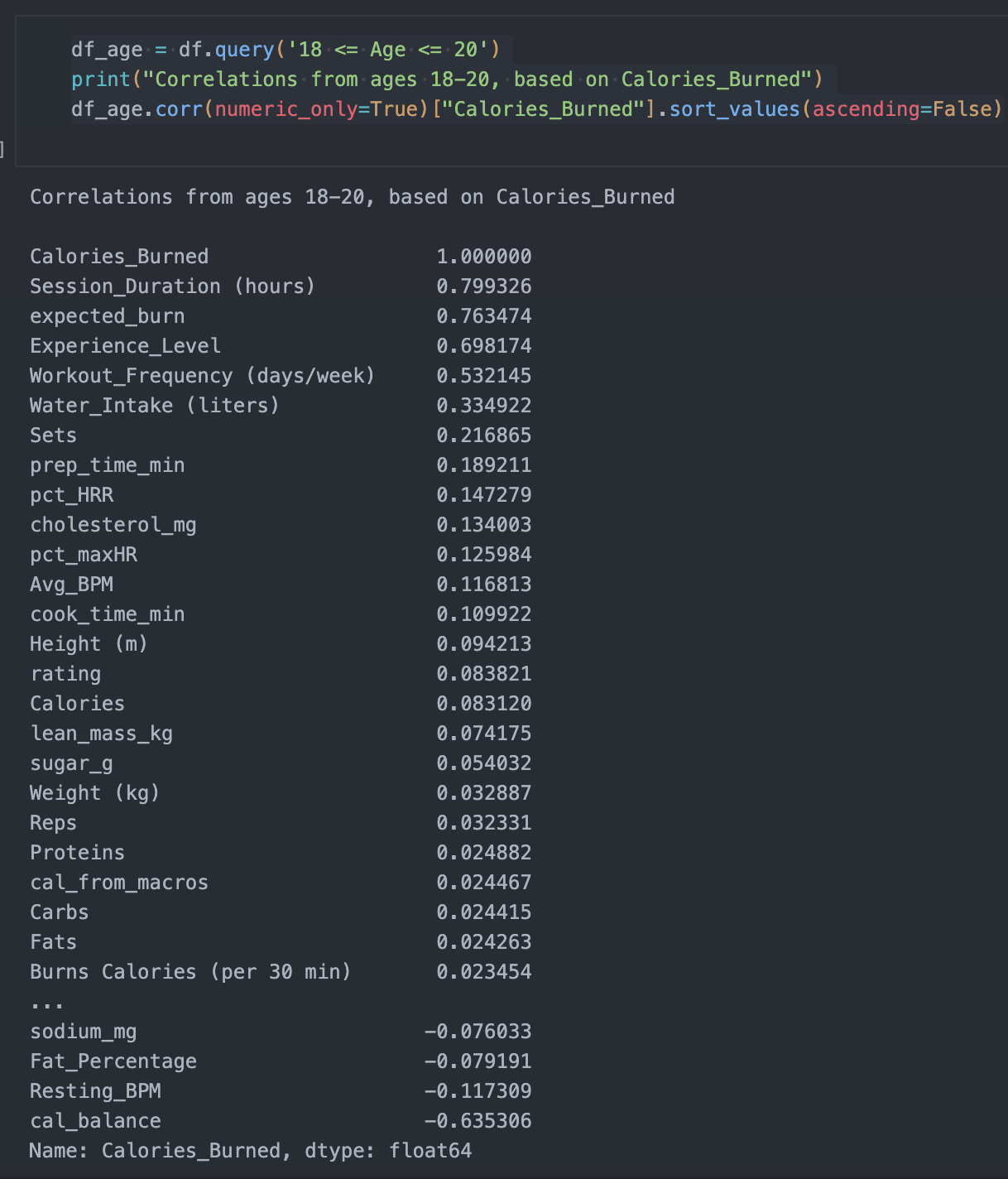
Through analyzation I was kind of shocked that a lot of factors didn't really correlate to each other. A lot of models that I tested had very poor R^2, MAE, RMSE scores, which suggested that my dataset had poor correlation in general, it wasn't until I looked deeper into the data that I could find out correlations.
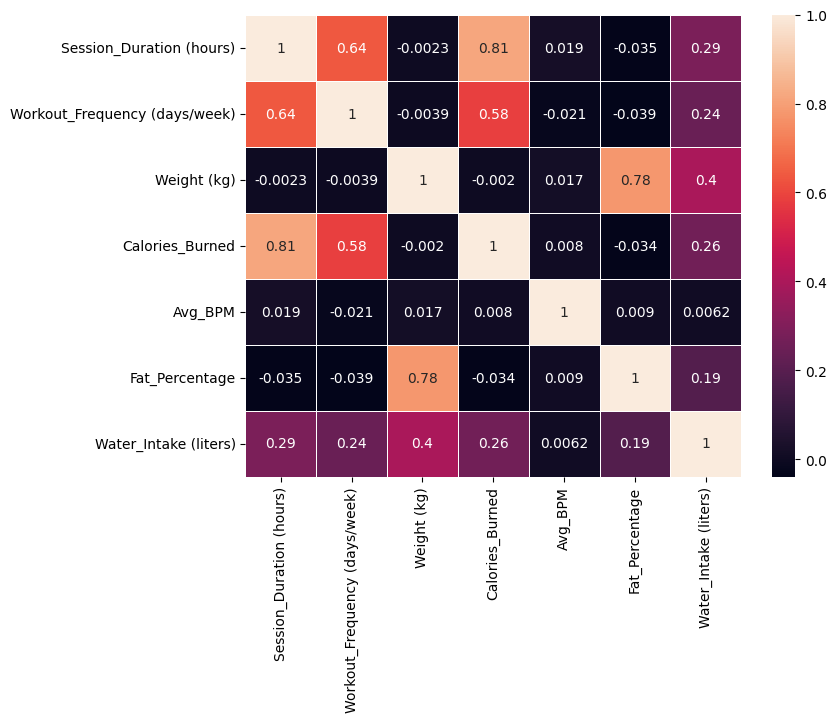
I developed a heatmap in order to best find out correlations after not having much luck with just picking out columns that seemed like they would just be a good fit for each other. This heatmap was extremely useful for finding out a greater relationship between my variables.
I had a lot of problems with multicolinearity, as there were so many times that different characteristics in the dataset looked like they had correlations with each other, when really it was just a bunch of other factors that made it look like they had correlation. There were other areas that didn't look like there was correlations at all, when I was sure that in general common sense would tell you that there was supposed to be a definite correlation.
Checking further for correlation
Checking for further correlation allows me to single out columns, the pre-processesing phase kind of was a continous process for this project. I had to constantly go back and check variables, check scores for r^2 to see if there was any correlation. With the graphs it was a matter of targeting certain columns for visualizations.
Modeling
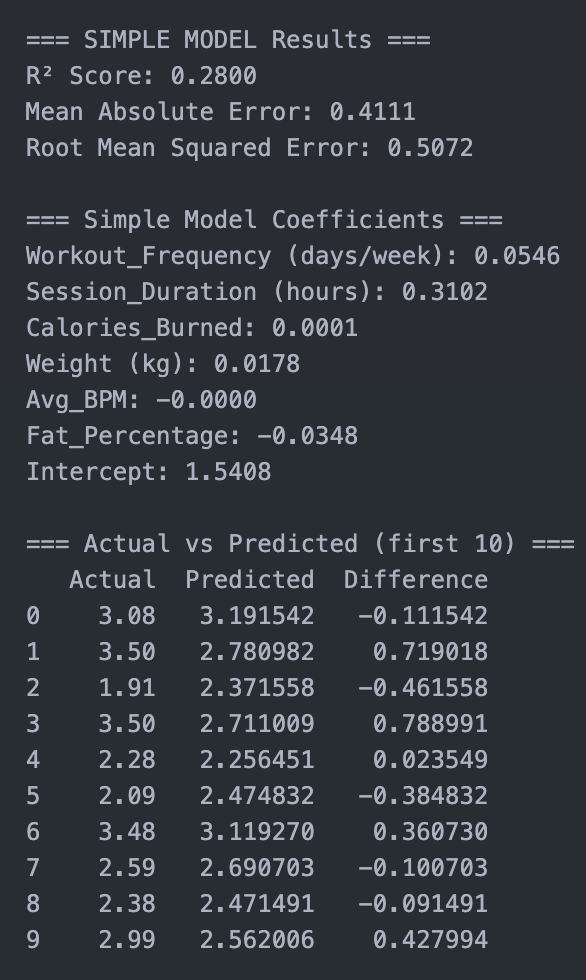
Experiment 1
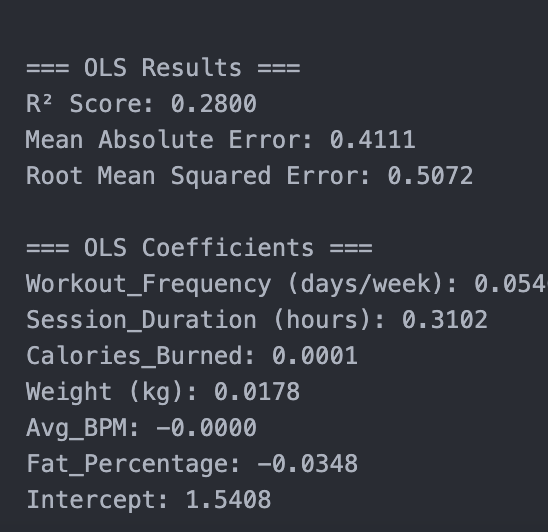
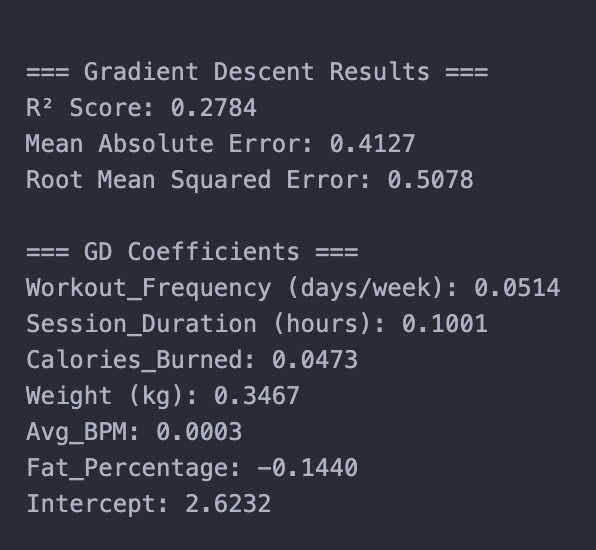
Results:
For the first experiment, it was kind of a failure, due to the low scores and the fact that the predicted scores were kind of off from the actual scores. The r^2 score was .2800, MAE: 0.41111, RMSE: 0.5702
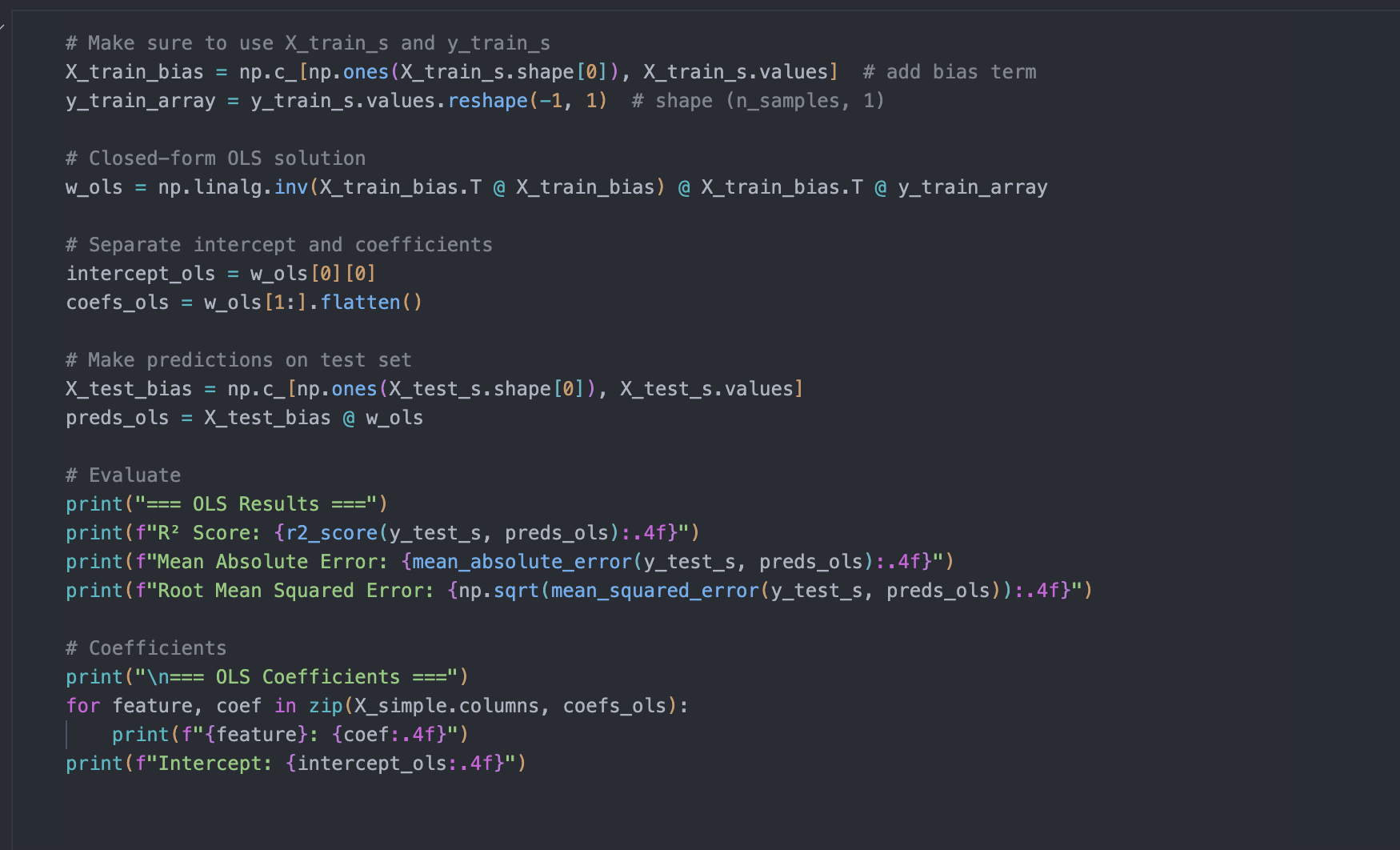
OLS
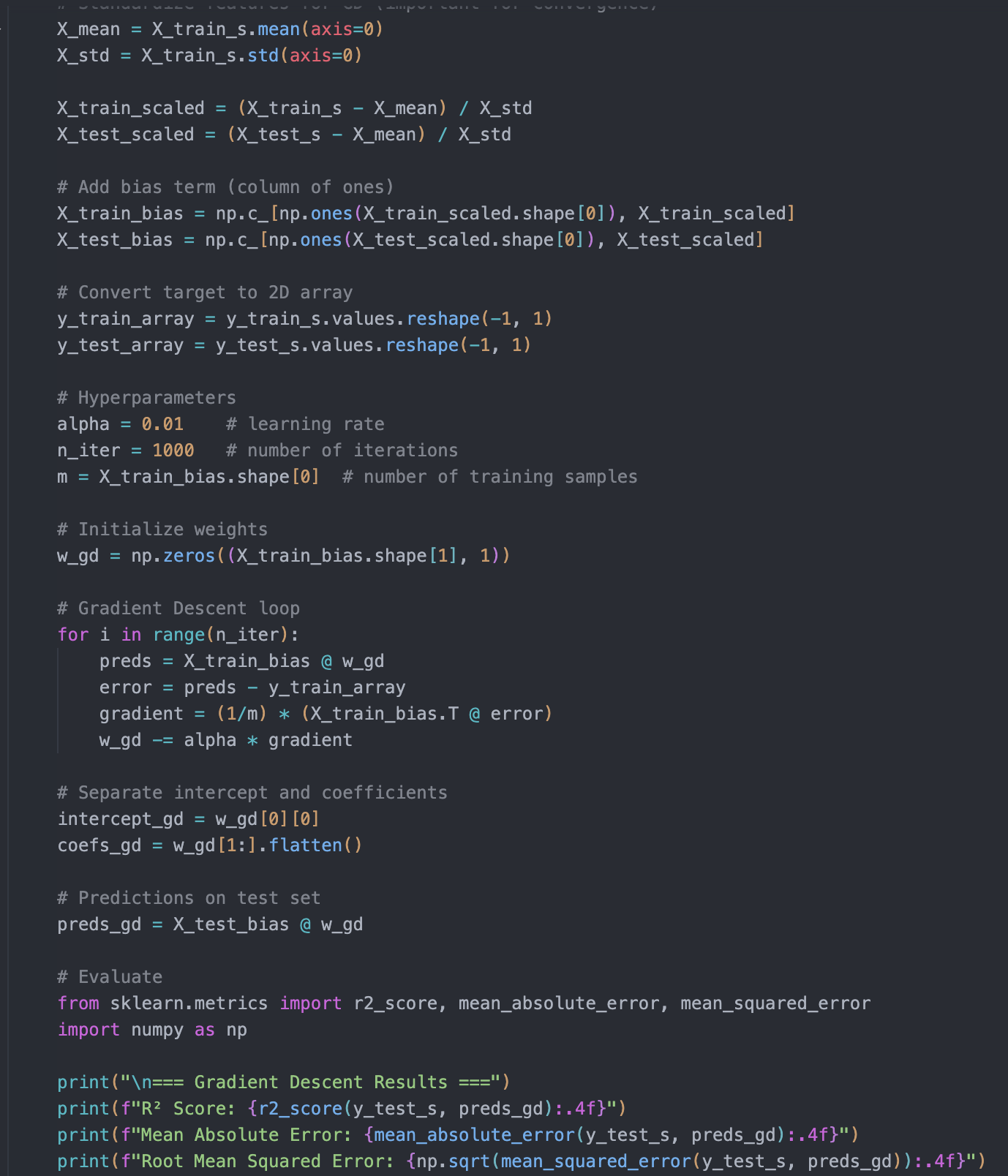
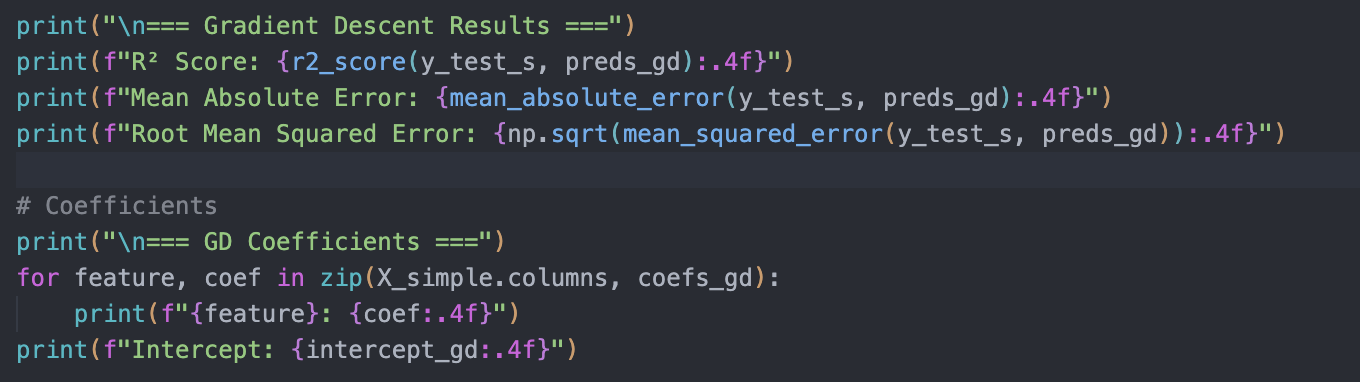
Gradient Descent
Experiment 2: Lasso Regression
Since my dataset had a lot of datapoints in general, I used lasso regression for my next model in order to reduce multicolinearity and reduce overfitting.
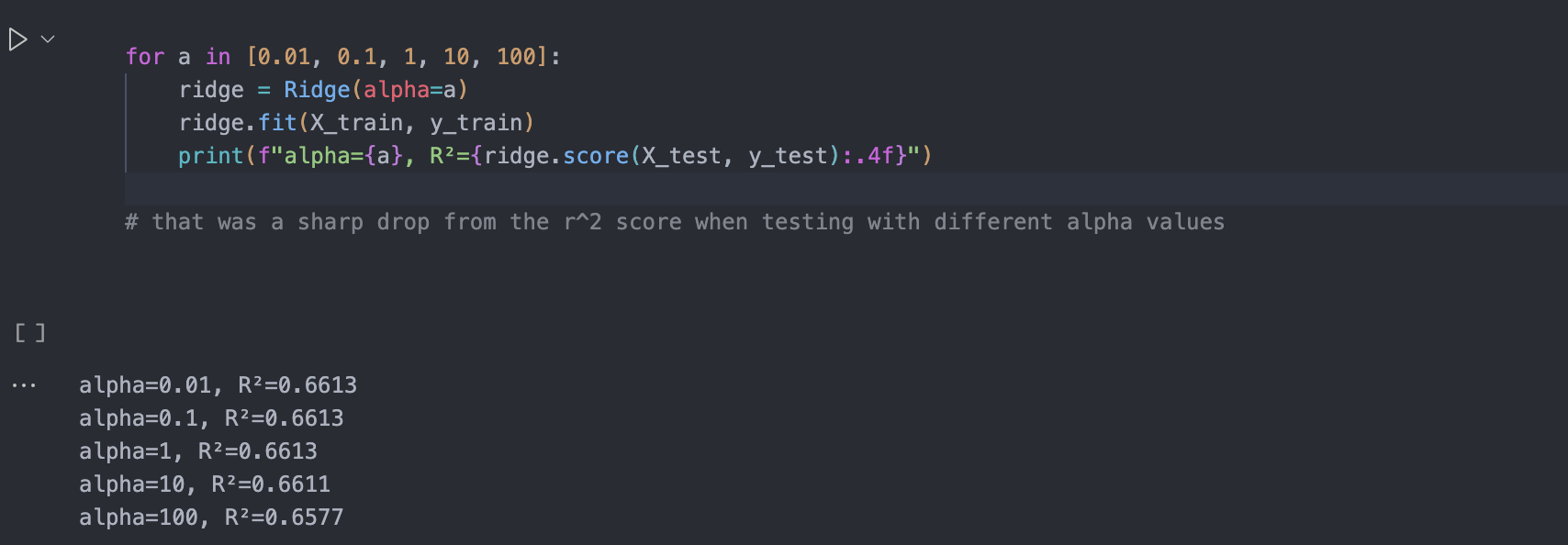
Ridge Regression (without scaling)
Using a ridge regression without scaling brought more or less the same results as linear regression on the same columns. Since ridge regression penalizes large coeifficients, then the penalty will disproportionately affect large values. This is why scaling is important
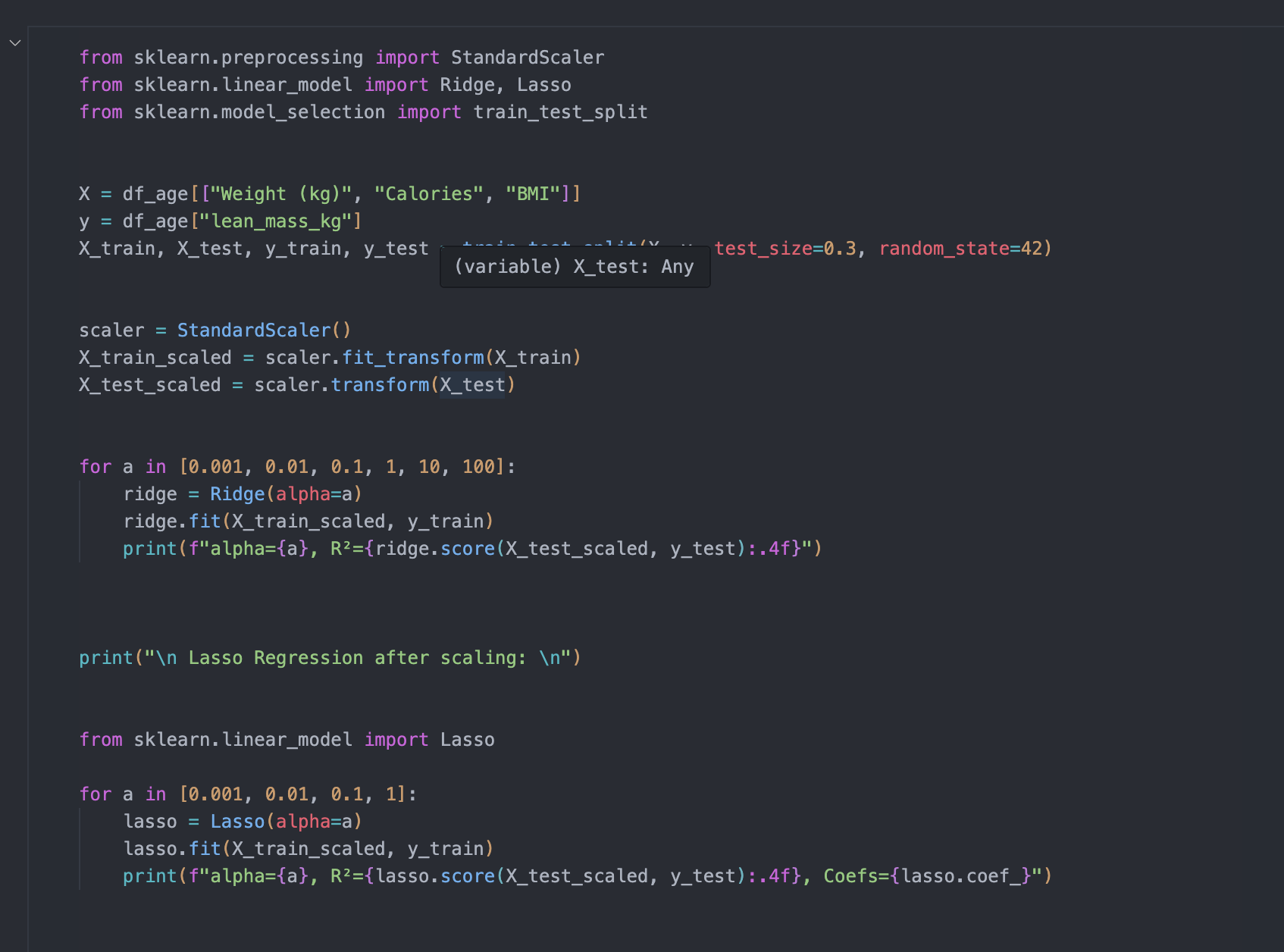
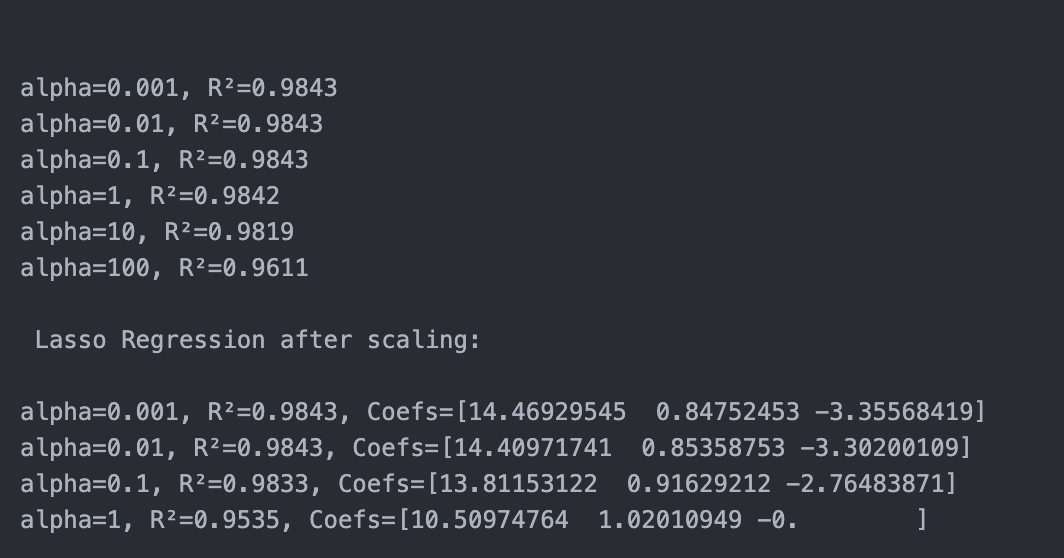
Experiment 3: Ridge Regression (scaled) and lasso Regression
Impact
This project could be useful towards people who want to see if there is any correlation between different factors, when it comes to exercise(itensity, persistence, amount of weight used per exercise, etc), however this data is collected from a large dataset. I feel like results would be even more accurate if there was more information on how this data was collected. If it was gained from different regions, what groups of people was the data collected from?, how diverse is the data (did you interview people from different ethnicities, nationalities, age-groups, gym-goers vs non gym-goers). Getting my statistics accurate is also relevant, I shouldn't try to force potential dependant correlations when there might not be a correlation in the first place, or its more complex in the first place. There could be multiple variables influencing another variable, when I only see one variable that is correlated, and therefore paint a misleading picture of the problem as a whole.
Conclusion
To wrap it up, I think there should definitely be more research on the relation to these categories, as I'm certain with more detailed data, there could defnitely be different conclusions related to this topic as a whole. Certain variables I thought were related turned out to not have much of a correlation, and when I really thought about it after, it definitely made a bit more sense.